

















把文本變成畫作,AI對藝術“下手”了
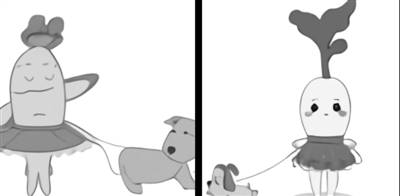
圖為人工智能系統 DALL·E根據文本“穿著芭蕾舞裙遛狗的小蘿卜”繪制的圖像
圖片來源:OpenAI官網
自然語言處理與視覺處理,都重在對不同模態數據所包含的語義信息進行識別和理解,但是兩種數據的語義表現形式和處理方法不同,導致存在所謂的“語義壁壘”,現在這種壁壘正在被AI打破。
◎本報記者 馬愛平
1月初,美國人工智能公司OpenAI推出兩個跨越文本與圖像次元的模型:DALL·E和CLIP,前者可以基於文本生成圖像,后者則可以基於文本對圖片進行分類。這個突破說明通過文字語言來操縱視覺概念現在已經觸手可及。自然語言處理和視覺處理的邊界已經被打破,多模態AI系統正在逐步建立。
“數據的來源或者形式是多種多樣的,每一種都可以稱為一種模態。例如圖像、視頻、聲音、文字、紅外、深度等都是不同模態的數據。單模態AI系統隻能處理單個模態的數據。例如對於人臉識別系統或者語音識別系統來說,它們各自隻能處理圖像和聲音數據。”中國科學院自動化研究所副研究員黃岩在接受科技日報記者採訪時表示。
相對而言,多模態AI系統可以同時處理不止一種模態的數據,而且能夠結合多種模態數據進行綜合分析。“例如服務機器人系統或者無人駕駛系統就是典型的多模態系統,它們在導航的過程中會實時採集視頻、深度、紅外等多種模態的數據,進行綜合分析后選擇合適的行駛路線。”黃岩說。
不同層次任務強行關聯會產生“壁壘”
就像人類有視覺、嗅覺、聽覺一樣,AI也有自己的“眼鼻嘴”,而為了研究的針對性和深入,科學家們通常會將其分為計算機視覺、自然語言處理、語音識別等研究領域,分門別類地解決不同的實際問題。
自然語言處理與視覺處理分別是怎樣的過程,二者之間為什麼會有壁壘?
語義是指文字、圖像或符號之間的構成關系及意義。“自然語言處理與視覺處理,都重在對不同模態數據所包含的語義信息進行識別和理解,但是兩種數據的語義表現形式和處理方法不同,導致存在所謂的‘語義壁壘’。”黃岩說。
視覺處理中最常見的數據就是圖像,每個圖像是由不同像素點排列而成的二維結構。像素點本身不具有任何語義類別信息,即無法僅憑一個像素點將其定義為圖像數據,因為像素點本身隻包含0到255之間的一個像素值。
“例如對於一張人臉圖像來說,如果我們隻看其中某些像素點是無法識別人臉圖像這一語義類別信息的。因此,目前計算機視覺領域的研究人員更多研究的是如何讓人工智能整合像素點數據,判斷這個數據集合的語義類別。”黃岩說。
“語言數據最常見的就是句子,是由不同的詞語序列化構成的一維結構。不同於圖像像素,文本中每個詞語已經包含了非常明確的語義類別信息。而自然語言處理則是在詞語的基礎上,進行更加高級的語義理解。”黃岩說,例如相同詞語排列的順序不同將產生不同的語義、多個句子聯合形成段落則可以推理出隱含語義信息。
可以說,自然語言處理主要研究實現人與計算機直接用自然語言進行有效信息交流,這個過程包括自然語言理解和自然語言生成。自然語言理解是指計算機能夠理解人類語言的意義,讀懂人類語言的潛在含義﹔自然語言生成則是指計算機能以自然語言文本來表達它想要達到的意圖。
由此可以看出,自然語言處理要解決的問題的層次深度超過了計算機視覺,自然語言處理是以理解人類的世界為目標,而計算機視覺所完成的就是所見即所得。這是兩個不同層次的任務。目前來說,自然語言處理在語義分析層面來說要高於視覺處理,二者是不對等的。如果強行將兩者進行語義關聯的話,則會產生“語義壁壘”。
AI打破自然語言處理和視覺處理的邊界
此前,OpenAI斥巨資打造的自然語言處理模型GPT-3,擁有1750億超大參數量,是自然語言處理領域最強AI模型。人們發現GPT-3不僅能夠答題、寫文章、做翻譯,還能生成代碼、做數學推理、數據分析、畫圖表、制作簡歷。自2020年5月首次推出以來,GPT-3憑借驚人的文本生成能力受到廣泛關注。
與GPT-3一樣,DALL·E也是一個具有120億參數的基於Transformer架構的語言模型,不同的是,GPT-3生成的是文本,DALL·E生成的是圖像。
在互聯網上,OpenAI大秀了一把DALL·E的“超強想象力”,隨意輸入一句話,DALL·E就能生成相應圖片,這個圖片內容可能是現實世界已經存在的,也可能是根據自己的理解創造出來的。
此前,關於視覺領域的深度學習方法一直存在三大挑戰——訓練所需大量數據集的採集和標注,會導致成本攀升﹔訓練好的視覺模型一般隻擅長一類任務,遷移到其他任務需要花費巨大成本﹔即使在基准測試中表現良好,在實際應用中可能也不如人意。
對此,OpenAI聯合創始人曾發文聲稱,語言模型或是一種解決方案,可以嘗試通過文本來修改和生成圖像。基於這一願景,CLIP應運而生。隻需要提供圖像類別的文本描述,CLIP就能將圖像進行分類。
至此,AI已經打破了自然語言處理和視覺處理的邊界。“這主要得益於計算機視覺領域中語義類別分析方面的飛速發展,使得AI已經能夠進一步進行更高層次的視覺語義理解。”黃岩說。
具體來說,隨著深度學習的興起,計算機視覺領域從2012年至今已經接連攻克一般自然場景下的目標識別、檢測、分割等語義類別分析任務。2015年至今,越來越多的視覺研究者們開始提出和研究更加高層的語義理解任務,包括基於圖像生成語言描述、用語言搜索圖片、面向圖像的語言問答等。
“這些語義理解任務通常都需要聯合視覺模型和語言模型才能夠解決,因此出現了第一批橫跨視覺領域和語言領域的研究者。”黃岩說,在他們推動下,兩個領域開始相互借鑒優秀模型和解決問題的思路,並進一步影響到更多傳統視覺和語言處理任務。
多模態交互方式會帶來全新的應用
隨著人工智能技術發展,科學家也正在不斷突破不同研究領域之間的界限,自然語言處理和視覺處理的交叉融合並不是個例。
“語音識別事實上已經加入其中,最近業內出現很多研究視覺+語音的新任務,例如基於一段語音生成人臉圖像或者跳舞視頻。”黃岩說,但是要注意到,語音其實與語言本身在內容上可能具有較大的重合性。在現在語音識別技術非常成熟的前提下,完全可以先對語音進行識別將其轉換為語言,進而把任務轉換為語言與圖像交互的常規問題。
無論是DALL·E還是CLIP,都採用不同的方法在多模態學習領域跨出了令人驚喜的一步。今后,文本和圖像的界限是否會被進一步打破,能否順暢地用文字“控制”圖像的分類和生成,將會給現實生活帶來怎樣的改變,都值得期待。
對於多模態交互方式可能會帶來哪些全新應用?黃岩舉了兩個具有代表性的例子。
第一個是手機的多模態語音助手。該技術可以豐富目前手機語音智能助手的功能和應用范圍。目前的手機助手隻能進行語音單模態交互,未來可以結合手機相冊等視覺數據、以及網絡空間中的語言數據來進行更加多樣化的推薦、查詢、問答等操作。
第二個是機器人的多模態導航。該技術可以提升服務機器人與人在視覺和語音(或語言)方面的交互能力,例如未來可以告訴機器人“去會議室看看有沒有電腦”,機器人在理解語言指令的情況下,就能夠結合視覺、深度等信息進行導航和查找。
分享讓更多人看到 
相關新聞
人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139
廣播電視節目制作經營許可証(廣媒)字第172號 | 互聯網藥品信息服務資格証書(京)-非經營性-2016-0098
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2021 by www.people.com.cn. all rights reserved




-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
